
Homographs (words that share the same spelling but have different meanings) can really put machine translation (MT) systems in a pickle. Is bass a fish or a guitar? Such ambiguities can make localization specialists wary of relying on MT, knowing that human translators have the upper hand when it comes to intuition and experience. However, thanks to advances in neural machine translation (NMT), MT systems are getting much better at cracking the code of homographs.
Contextual analysis in NMT
Modern translation systems rely heavily on neural networks, particularly Transformer-based models like those used in Google Translate and DeepL. These models process entire sentences rather than translating words in isolation, allowing them to derive meaning from context. By analyzing the relationships between words, NMT models can infer whether a homograph is being used as a noun, verb, adjective, or another part of speech.
The word lead, for example:
- In “She will lead the discussion,” it functions as a verb.
- In “The pipes contain lead,” it is a noun referring to a metal.
Let’s translate these sentences using Google Translate:
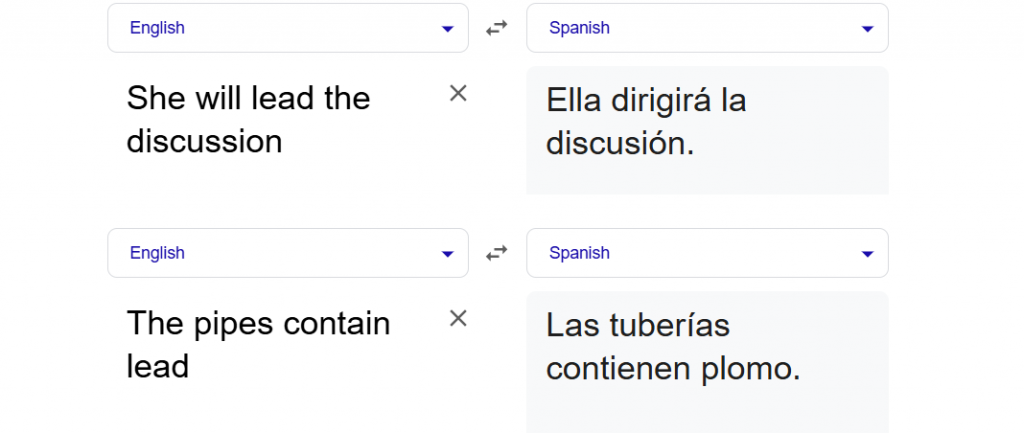
A neural model evaluates the surrounding words and sentence structure to choose the most appropriate translation. Since different languages may have distinct words for these meanings (e.g., lead the verb translates to dirigir in Spanish, while the noun lead translates to plomo), accurate contextual analysis is crucial.
Part-of-speech tagging and syntactic parsing
Part-of-speech tagging helps the system determine a word’s grammatical role by assigning a label to each word in a sentence based on its function.. Modern statistical and neural approaches use large datasets to train models that recognize these roles dynamically.
Syntactic parsing further refines this process by analyzing the structure of a sentence. A well-trained system can distinguish between identical words used in different grammatical functions, so you’re getting a more accurate translation. However, some languages pose difficulting for both POS tagging and syntactic parsing, so neither method is foolproof.
Word-sense disambiguation and word embeddings
Word-sense disambiguation is the process of understanding the meaning of a word based on its relationship with other words. Neural networks achieve this using word embeddings, which are mathematical representations of words that capture their meanings based on context.
Let’s say a translation model encounters the word bat. It will analyze the surrounding words to determine whether it refers to the flying mammal or a piece of sports equipment. If the sentence mentions things like cave or wings, the model is more likely to choose the animal-related meaning. Conversely, if words like baseball or hit appear nearby, the model will interpret bat as the sports tool.
Wrapping up
Machine translation models continuously improve because they are trained on vast amounts of bilingual and monolingual text. While today, homographs still pose challenges, especially in ambiguous or short phrases without sufficient context, the future of MT will likely involve even more advanced techniques, making translations more accurate than ever before.